How to Upload the json to a Cloudkey?
Loading JSON information from Cloud Storage
Loading JSON files from Deject Storage
Y'all can load newline delimited JSON information from Deject Storage into a new table or partition, or append to or overwrite an existing table or division. When your data is loaded into BigQuery, it is converted into columnar format for Capacitor (BigQuery's storage format).
When you load data from Cloud Storage into a BigQuery table, the dataset that contains the table must be in the same regional or multi- regional location as the Cloud Storage bucket.
The newline delimited JSON format is the same format as the JSON Lines format.
For data about loading JSON information from a local file, run across Loading data from local files.
Limitations
When y'all load JSON files into BigQuery, note the following:
- JSON data must exist newline delimited. Each JSON object must be on a separate line in the file.
- If you lot use gzip compression, BigQuery cannot read the data in parallel. Loading compressed JSON data into BigQuery is slower than loading uncompressed information.
- Y'all cannot include both compressed and uncompressed files in the same load job.
- The maximum size for a gzip file is 4 GB.
-
BigQuery does non back up maps or dictionaries in JSON, due to potential lack of schema data in a pure JSON dictionary. For example, to correspond a list of products in a cart
"products": {"my_product": xl.0, "product2" : sixteen.five}is not valid, but"products": [{"product_name": "my_product", "amount": xl.0}, {"product_name": "product2", "amount": xvi.5}]is valid.If you demand to go along the entire JSON object, and then information technology should be put into a
stringcavalcade, which can be queried using JSON functions. -
If you use the BigQuery API to load an integer outside the range of [-253+1, 253-1] (commonly this means larger than 9,007,199,254,740,991), into an integer (INT64) column, pass it as a string to avoid data corruption. This issue is acquired by a limitation on integer size in JSON/ECMAScript. For more than information, run into the Numbers section of RFC 7159.
- When you load CSV or JSON data, values in
Engagementcolumns must use the dash (-) separator and the date must be in the following format:YYYY-MM-DD(twelvemonth-month-day). - When you load JSON or CSV data, values in
TIMESTAMPcolumns must employ a dash (-) separator for the date portion of the timestamp, and the engagement must be in the post-obit format:YYYY-MM-DD(year-month-mean solar day). Thehh:mm:ss(hour-minute-second) portion of the timestamp must use a colon (:) separator.
Before you brainstorm
Grant Identity and Access Management (IAM) roles that give users the necessary permissions to perform each task in this document.
Required permissions
To load information into BigQuery, you lot demand IAM permissions to run a load task and load data into BigQuery tables and partitions. If you are loading data from Deject Storage, you too need IAM permissions to access the bucket that contains your information.
Permissions to load data into BigQuery
To load information into a new BigQuery table or partition or to suspend or overwrite an existing table or partition, you need the post-obit IAM permissions:
-
bigquery.tables.create -
bigquery.tables.updateData -
bigquery.tables.update -
bigquery.jobs.create
Each of the following predefined IAM roles includes the permissions that you need in order to load data into a BigQuery table or partition:
-
roles/bigquery.dataEditor -
roles/bigquery.dataOwner -
roles/bigquery.admin(includes thebigquery.jobs.createpermission) -
bigquery.user(includes thebigquery.jobs.createpermission) -
bigquery.jobUser(includes thebigquery.jobs.createpermission)
Additionally, if you accept the bigquery.datasets.create permission, you can create and update tables using a load job in the datasets that you lot create.
For more information on IAM roles and permissions in BigQuery, see Predefined roles and permissions.
Permissions to load data from Cloud Storage
To load data from a Cloud Storage bucket, you need the following IAM permissions:
-
storage.objects.get -
storage.objects.list(required if you lot are using a URI wildcard)
The predefined IAM role roles/storage.objectViewer includes all the permissions you lot need in order to load data from a Deject Storage saucepan.
Loading JSON data into a new table
Yous can load newline delimited JSON data from Cloud Storage into a new BigQuery table past using one of the following:
- The Cloud Console
- The
bqcommand-line tool'due southbq loadcontrol - The
jobs.insertAPI method and configuring aloadjob - The client libraries
To load JSON data from Cloud Storage into a new BigQuery table:
Panel
-
In the Deject Console, open the BigQuery page.
Go to BigQuery
-
In the Explorer panel, aggrandize your projection and select a dataset.
-
Expand the Deportment option and click Open.
-
In the details panel, click Create table .
-
On the Create table folio, in the Source section:
-
For Create table from, select Deject Storage.
-
In the source field, browse to or enter the Deject Storage URI. You cannot include multiple URIs in the Deject Console, but wildcards are supported. The Cloud Storage bucket must exist in the same location as the dataset that contains the table you're creating.

-
For File format, select JSON (Newline delimited).
-
-
On the Create table page, in the Destination department:
-
For Dataset name, choose the appropriate dataset.

-
Verify that Tabular array type is prepare to Native table.
-
In the Table name field, enter the proper noun of the tabular array yous're creating in BigQuery.
-
-
In the Schema department, for Auto detect, check Schema and input parameters to enable schema auto detection. Alternatively, you lot tin can manually enter the schema definition past:
-
Enabling Edit every bit text and entering the table schema as a JSON array.

-
Using Add field to manually input the schema.

-
-
(Optional) To partition the table, choose your options in the Segmentation and cluster settings. For more information, encounter Creating partitioned tables.
-
(Optional) For Partitioning filter, click the Require partition filter box to crave users to include a
WHEREclause that specifies the partitions to query. Requiring a division filter can reduce cost and improve performance. For more information, meet Querying partitioned tables. This option is unavailable if No partitioning is selected. -
(Optional) To cluster the table, in the Clustering order box, enter between ane and four field names.
-
(Optional) Click Advanced options.
- For Write preference, leave Write if empty selected. This selection creates a new table and loads your information into it.
- For Number of errors immune, take the default value of
0or enter the maximum number of rows containing errors that can be ignored. If the number of rows with errors exceeds this value, the job results in aninvalidbulletin and fails. - For Unknown values, check Ignore unknown values to ignore any values in a row that are not present in the table's schema.
- For Encryption, click Customer-managed key to utilize a Cloud Key Direction Service fundamental. If you leave the Google-managed key setting, BigQuery encrypts the data at rest.
-
Click Create table.
bq
Use the bq load command, specify NEWLINE_DELIMITED_JSON using the --source_format flag, and include a Deject Storage URI. You can include a single URI, a comma-separated list of URIs, or a URI containing a wildcard. Supply the schema inline, in a schema definition file, or use schema auto-detect.
(Optional) Supply the --location flag and set up the value to your location.
Other optional flags include:
-
--max_bad_records: An integer that specifies the maximum number of bad records immune before the entire job fails. The default value is0. At most, five errors of any type are returned regardless of the--max_bad_recordsvalue. -
--ignore_unknown_values: When specified, allows and ignores extra, unrecognized values in CSV or JSON information. -
--autodetect: When specified, enable schema automobile-detection for CSV and JSON data. -
--time_partitioning_type: Enables time-based partitioning on a tabular array and sets the partition blazon. Possible values areHOUR,24-hour interval,MONTH, andYr. This flag is optional when you create a table partitioned on aDATE,DATETIME, orTIMESTAMPcolumn. The default partition type for time-based division isDAY. You cannot change the division specification on an existing tabular array. -
--time_partitioning_expiration: An integer that specifies (in seconds) when a time-based partition should exist deleted. The expiration time evaluates to the partition's UTC date plus the integer value. -
--time_partitioning_field: TheDATEorTIMESTAMPcavalcade used to create a partitioned table. If time-based segmentation is enabled without this value, an ingestion-fourth dimension partitioned table is created. -
--require_partition_filter: When enabled, this selection requires users to include aWHEREclause that specifies the partitions to query. Requiring a partitioning filter can reduce cost and improve performance. For more data, see Querying partitioned tables. -
--clustering_fields: A comma-separated listing of up to four cavalcade names used to create a clustered table. -
--destination_kms_key: The Deject KMS key for encryption of the tabular array information.For more information on partitioned tables, see:
- Creating partitioned tables
For more information on clustered tables, see:
- Creating and using clustered tables
For more data on table encryption, meet:
- Protecting data with Cloud KMS keys
To load JSON data into BigQuery, enter the following command:
bq --location=LOCATION load \ --source_format=FORMAT \ DATASET.Tabular array \ PATH_TO_SOURCE \ SCHEMA
Replace the following:
-
LOCATION: your location. The--locationflag is optional. For example, if yous are using BigQuery in the Tokyo region, you lot can set the flag'south value toasia-northeast1. You tin set a default value for the location using the .bigqueryrc file. -
FORMAT:NEWLINE_DELIMITED_JSON. -
DATASET: an existing dataset. -
Table: the name of the table into which you're loading data. -
PATH_TO_SOURCE: a fully qualified Cloud Storage URI or a comma-separated list of URIs. Wildcards are likewise supported. -
SCHEMA: a valid schema. The schema tin be a local JSON file, or it tin can be typed inline as part of the control. If you use a schema file, practise not give it an extension. Yous tin likewise use the--autodetectflag instead of supplying a schema definition.
Examples:
The following command loads information from gs://mybucket/mydata.json into a tabular array named mytable in mydataset. The schema is defined in a local schema file named myschema.
bq load \ --source_format=NEWLINE_DELIMITED_JSON \ mydataset.mytable \ gs://mybucket/mydata.json \ ./myschema The following command loads data from gs://mybucket/mydata.json into a new ingestion-fourth dimension partitioned table named mytable in mydataset. The schema is defined in a local schema file named myschema.
bq load \ --source_format=NEWLINE_DELIMITED_JSON \ --time_partitioning_type=Solar day \ mydataset.mytable \ gs://mybucket/mydata.json \ ./myschema The following command loads data from gs://mybucket/mydata.json into a partitioned table named mytable in mydataset. The table is partitioned on the mytimestamp column. The schema is defined in a local schema file named myschema.
bq load \ --source_format=NEWLINE_DELIMITED_JSON \ --time_partitioning_field mytimestamp \ mydataset.mytable \ gs://mybucket/mydata.json \ ./myschema The following control loads data from gs://mybucket/mydata.json into a table named mytable in mydataset. The schema is auto detected.
bq load \ --autodetect \ --source_format=NEWLINE_DELIMITED_JSON \ mydataset.mytable \ gs://mybucket/mydata.json The following command loads data from gs://mybucket/mydata.json into a table named mytable in mydataset. The schema is divers inline in the format FIELD:DATA_TYPE, FIELD:DATA_TYPE .
bq load \ --source_format=NEWLINE_DELIMITED_JSON \ mydataset.mytable \ gs://mybucket/mydata.json \ qtr:STRING,sales:FLOAT,year:String The following command loads data from multiple files in gs://mybucket/ into a table named mytable in mydataset. The Deject Storage URI uses a wildcard. The schema is machine detected.
bq load \ --autodetect \ --source_format=NEWLINE_DELIMITED_JSON \ mydataset.mytable \ gs://mybucket/mydata*.json The following control loads data from multiple files in gs://mybucket/ into a table named mytable in mydataset. The control includes a comma- separated list of Deject Storage URIs with wildcards. The schema is defined in a local schema file named myschema.
bq load \ --source_format=NEWLINE_DELIMITED_JSON \ mydataset.mytable \ "gs://mybucket/00/*.json","gs://mybucket/01/*.json" \ ./myschema API
-
Create a
loadjob that points to the source data in Cloud Storage. -
(Optional) Specify your location in the
locationproperty in thejobReferencesection of the job resource. -
The
source URIsproperty must be fully qualified, in the formatgs://Bucket/OBJECT. Each URI tin can contain ane '*' wildcard character. -
Specify the JSON data format by setting the
sourceFormatproperty toNEWLINE_DELIMITED_JSON. -
To check the job status, call
jobs.become(JOB_ID*), replacingJOB_IDwith the ID of the task returned by the initial asking.- If
status.land = DONE, the job completed successfully. - If the
condition.errorResultbelongings is present, the request failed, and that object includes information describing what went wrong. When a request fails, no tabular array is created and no data is loaded. - If
status.errorResultis absent, the job finished successfully; although, there might have been some nonfatal errors, such as issues importing a few rows. Nonfatal errors are listed in the returned task object'sstatus.errorsbelongings.
- If
API notes:
-
Load jobs are atomic and consistent; if a load job fails, none of the data is bachelor, and if a load job succeeds, all of the data is available.
-
As a best practice, generate a unique ID and laissez passer it as
jobReference.jobIdwhen callingjobs.insertto create a load job. This approach is more robust to network failure because the customer tin can poll or retry on the known job ID. -
Calling
jobs.inserton a given chore ID is idempotent. Yous can retry equally many times equally you similar on the same job ID, and at most, one of those operations succeed.
C#
Before trying this sample, follow the C# setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery C# API reference documentation.
Apply theBigQueryClient.CreateLoadJob() method to start a load job from Deject Storage. To employ newline-delimited JSON, create a CreateLoadJobOptions object and set its SourceFormat property to FileFormat.NewlineDelimitedJson. Go
Before trying this sample, follow the Get setup instructions in the BigQuery quickstart using client libraries. For more information, come across the BigQuery Get API reference documentation.
Coffee
Before trying this sample, follow the Java setup instructions in the BigQuery quickstart using customer libraries. For more information, see the BigQuery Coffee API reference documentation.
Use the LoadJobConfiguration.builder(tableId, sourceUri) method to offset a load job from Cloud Storage. To use newline-delimited JSON, use the LoadJobConfiguration.setFormatOptions(FormatOptions.json()).Node.js
Before trying this sample, follow the Node.js setup instructions in the BigQuery quickstart using client libraries. For more than information, see the BigQuery Node.js API reference documentation.
PHP
Earlier trying this sample, follow the PHP setup instructions in the BigQuery quickstart using client libraries. For more information, run across the BigQuery PHP API reference documentation.
Python
Before trying this sample, follow the Python setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Python API reference documentation.
Use the Client.load_table_from_uri() method to start a load job from Cloud Storage. To utilise newline-delimited JSON, ready the LoadJobConfig.source_format belongings to the cordNEWLINE_DELIMITED_JSON and pass the job config equally the job_config argument to the load_table_from_uri() method. Scarlet
Before trying this sample, follow the Cherry-red setup instructions in the BigQuery quickstart using client libraries. For more data, see the BigQuery Ruby API reference documentation.
Use the Dataset.load_job() method to start a load job from Deject Storage. To apply newline-delimited JSON, set up theformat parameter to "json". Loading nested and repeated JSON data
BigQuery supports loading nested and repeated data from source formats that support object-based schemas, such as JSON, Avro, ORC, Parquet, Firestore, and Datastore.
One JSON object, including whatsoever nested/repeated fields, must appear on each line.
The following example shows sample nested/repeated information. This table contains information virtually people. It consists of the post-obit fields:
-
id -
first_name -
last_name -
dob(date of nascency) -
addresses(a nested and repeated field)-
addresses.status(current or previous) -
addresses.accost -
addresses.city -
addresses.state -
addresses.zip -
addresses.numberOfYears(years at the address)
-
The JSON data file would look like the following. Observe that the address field contains an assortment of values (indicated by [ ]).
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"condition":"electric current","address":"123 First Avenue","metropolis":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Master Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]} {"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"electric current","accost":"789 Whatever Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Master Street","city":"Hoboken","country":"NJ","nix":"44444","numberOfYears":"3"}]} The schema for this table would expect like the following:
[ { "name": "id", "type": "STRING", "manner": "NULLABLE" }, { "proper name": "first_name", "type": "STRING", "fashion": "NULLABLE" }, { "name": "last_name", "type": "String", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "fashion": "NULLABLE" }, { "proper noun": "addresses", "type": "Record", "way": "REPEATED", "fields": [ { "proper name": "status", "blazon": "STRING", "manner": "NULLABLE" }, { "name": "address", "type": "String", "mode": "NULLABLE" }, { "proper noun": "city", "type": "STRING", "fashion": "NULLABLE" }, { "proper name": "state", "type": "STRING", "fashion": "NULLABLE" }, { "name": "zip", "type": "STRING", "way": "NULLABLE" }, { "proper noun": "numberOfYears", "type": "Cord", "mode": "NULLABLE" } ] } ] For information on specifying a nested and repeated schema, run into Specifying nested and repeated fields.
Appending to or overwriting a tabular array with JSON data
You tin can load additional data into a tabular array either from source files or by appending query results.
In the Deject Console, use the Write preference option to specify what activeness to take when y'all load data from a source file or from a query consequence.
You have the following options when you load additional information into a tabular array:
| Console option | bq tool flag | BigQuery API holding | Description |
|---|---|---|---|
| Write if empty | Not supported | WRITE_EMPTY | Writes the data just if the table is empty. |
| Append to tabular array | --noreplace or --replace=false; if --[no]replace is unspecified, the default is append | WRITE_APPEND | (Default) Appends the information to the end of the table. |
| Overwrite tabular array | --replace or --replace=true | WRITE_TRUNCATE | Erases all existing data in a table earlier writing the new information. This action also deletes the tabular array schema and removes any Cloud KMS key. |
If you load data into an existing tabular array, the load job can append the information or overwrite the tabular array.
You tin append or overwrite a table past using one of the following:
- The Cloud Console
- The
bqcommand-line tool'sbq loadcommand - The
jobs.insertAPI method and configuring aloadtask - The client libraries
Console
-
In the Cloud Console, open the BigQuery page.
Go to BigQuery
-
In the Explorer panel, expand your project and select a dataset.
-
Expand the Actions option and click Open up.
-
In the details panel, click Create table .
-
On the Create tabular array page, in the Source department:
-
For Create table from, select Cloud Storage.
-
In the source field, browse to or enter the Cloud Storage URI. You cannot include multiple URIs in the Cloud Panel, simply wildcards are supported. The Cloud Storage bucket must exist in the same location as the dataset that contains the table you're appending or overwriting.
-
For File format, select JSON (Newline delimited).
-
-
On the Create table folio, in the Destination section:
-
For Dataset proper name, cull the appropriate dataset.
-
In the Table proper noun field, enter the name of the tabular array you're appending or overwriting in BigQuery.
-
Verify that Table type is gear up to Native table.
-
-
In the Schema section, for Auto notice, bank check Schema and input parameters to enable schema auto detection. Alternatively, you lot can manually enter the schema definition past:
-
Enabling Edit as text and inbound the table schema as a JSON array.
-
Using Add field to manually input the schema.
-
-
For Segmentation and cluster settings, exit the default values. Yous cannot convert a tabular array to a partitioned or clustered table by appending or overwriting it. The Cloud Console does not back up appending to or overwriting partitioned or clustered tables in a load job.
-
Click Advanced options.
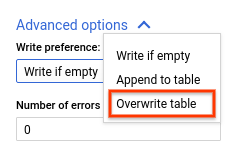
- For Write preference, choose Append to tabular array or Overwrite table.
- For Number of errors allowed, accept the default value of
0or enter the maximum number of rows containing errors that tin be ignored. If the number of rows with errors exceeds this value, the job results in aninvalidbulletin and fails. - For Unknown values, check Ignore unknown values to ignore any values in a row that are not present in the tabular array's schema.
-
For Encryption, click Client-managed primal to employ a Deject Primal Management Service cardinal. If you leave the Google-managed primal setting, BigQuery encrypts the data at residual.
-
Click Create table.
bq
Employ the bq load command, specify NEWLINE_DELIMITED_JSON using the --source_format flag, and include a Cloud Storage URI. You can include a single URI, a comma-separated list of URIs, or a URI containing a wildcard.
Supply the schema inline, in a schema definition file, or use schema auto-detect.
Specify the --replace flag to overwrite the table. Use the --noreplace flag to append data to the table. If no flag is specified, the default is to suspend data.
It is possible to modify the table's schema when you append or overwrite it. For more information on supported schema changes during a load operation, run into Modifying table schemas.
(Optional) Supply the --location flag and set up the value to your location.
Other optional flags include:
-
--max_bad_records: An integer that specifies the maximum number of bad records allowed earlier the entire job fails. The default value is0. At nearly, five errors of any blazon are returned regardless of the--max_bad_recordsvalue. -
--ignore_unknown_values: When specified, allows and ignores extra, unrecognized values in CSV or JSON data. -
--autodetect: When specified, enable schema motorcar-detection for CSV and JSON information. -
--destination_kms_key: The Deject KMS cardinal for encryption of the table data.
bq --location=LOCATION load \ --[no]supervene upon \ --source_format=FORMAT \ DATASET.Table \ PATH_TO_SOURCE \ SCHEMA
Supersede the following:
-
LOCATION: your location. The--locationflag is optional. You tin prepare a default value for the location using the .bigqueryrc file. -
FORMAT:NEWLINE_DELIMITED_JSON. -
DATASET: an existing dataset. -
TABLE: the name of the table into which you're loading data. -
PATH_TO_SOURCE: a fully qualified Deject Storage URI or a comma-separated list of URIs. Wildcards are as well supported. -
SCHEMA: a valid schema. The schema can be a local JSON file, or it can be typed inline equally function of the command. You can too use the--autodetectflag instead of supplying a schema definition.
Examples:
The following command loads information from gs://mybucket/mydata.json and overwrites a tabular array named mytable in mydataset. The schema is divers using schema car-detection.
bq load \ --autodetect \ --supplant \ --source_format=NEWLINE_DELIMITED_JSON \ mydataset.mytable \ gs://mybucket/mydata.json The following command loads data from gs://mybucket/mydata.json and appends information to a table named mytable in mydataset. The schema is defined using a JSON schema file — myschema.
bq load \ --noreplace \ --source_format=NEWLINE_DELIMITED_JSON \ mydataset.mytable \ gs://mybucket/mydata.json \ ./myschema API
-
Create a
loadtask that points to the source data in Cloud Storage. -
(Optional) Specify your location in the
locationproperty in thejobReferencedepartment of the job resource. -
The
source URIsholding must exist fully-qualified, in the formatgs://Bucket/OBJECT. You lot can include multiple URIs as a comma-separated listing. The wildcards are besides supported. -
Specify the data format by setting the
configuration.load.sourceFormatproperty toNEWLINE_DELIMITED_JSON. -
Specify the write preference by setting the
configuration.load.writeDispositionproperty toWRITE_TRUNCATEorWRITE_APPEND.
Go
Earlier trying this sample, follow the Go setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Go API reference documentation.
Java
Node.js
Before trying this sample, follow the Node.js setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Node.js API reference documentation.
PHP
Before trying this sample, follow the PHP setup instructions in the BigQuery quickstart using client libraries. For more than information, see the BigQuery PHP API reference documentation.
Python
To supercede the rows in an existing tabular array, set the LoadJobConfig.write_disposition property to the string WRITE_TRUNCATE.
Before trying this sample, follow the Python setup instructions in the BigQuery quickstart using client libraries. For more data, see the BigQuery Python API reference documentation.
Ruby
To replace the rows in an existing table, set the write parameter of Tabular array.load_job() to "WRITE_TRUNCATE".
Earlier trying this sample, follow the Ruby setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Ruby API reference documentation.
Loading hive-partitioned JSON data
BigQuery supports loading hive partitioned JSON information stored on Deject Storage and populates the hive partitioning columns equally columns in the destination BigQuery managed table. For more information, see Loading externally partitioned data.
Details of loading JSON data
This section describes how BigQuery parses various data types when loading JSON data.
Data types
Boolean. BigQuery can parse any of the following pairs for Boolean data: 1 or 0, true or simulated, t or f, aye or no, or y or due north (all case insensitive). Schema autodetection automatically detects any of these except 0 and one.
Bytes. Columns with BYTES types must be encoded every bit Base64.
Date. Columns with DATE types must exist in the format YYYY-MM-DD.
Datetime. Columns with DATETIME types must be in the format YYYY-MM-DD HH:MM:SS[.SSSSSS].
Geography. Columns with GEOGRAPHY types must incorporate strings in one of the following formats:
- Well-known text (WKT)
- Well-known binary (WKB)
- GeoJSON
If you lot use WKB, the value should exist hex encoded.
The following list shows examples of valid data:
- WKT:
Bespeak(ane 2) - GeoJSON:
{ "type": "Bespeak", "coordinates": [1, 2] } - Hex encoded WKB:
0101000000feffffffffffef3f0000000000000040
Before loading GEOGRAPHY data, likewise read Loading geospatial data.
Interval. Columns with INTERVAL types must be in ISO 8601 format PYMDTHMS, where:
- P = Designator that indicates that the value represents a elapsing. You must always include this.
- Y = Twelvemonth
- M = Month
- D = Twenty-four hour period
- T = Designator that denotes the time portion of the duration. You must always include this.
- H = Hour
- One thousand = Minute
- Southward = 2nd. Seconds tin can be denoted as a whole value or equally a fractional value of up to six digits, at microsecond precision.
You can signal a negative value by prepending a nuance (-).
The post-obit list shows examples of valid data:
-
P-10000Y0M-3660000DT-87840000H0M0S -
P0Y0M0DT0H0M0.000001S -
P10000Y0M3660000DT87840000H0M0S
To load INTERVAL data, you must use the bq load command and employ the --schema flag to specify a schema. You tin can't upload INTERVAL data by using the console.
Fourth dimension. Columns with Time types must be in the format HH:MM:SS[.SSSSSS].
Timestamp. BigQuery accepts various timestamp formats. The timestamp must include a date portion and a time portion.
-
The engagement portion can be formatted as
YYYY-MM-DDorYYYY/MM/DD. -
The timestamp portion must exist formatted as
HH:MM[:SS[.SSSSSS]](seconds and fractions of seconds are optional). -
The date and time must exist separated by a space or 'T'.
-
Optionally, the appointment and time can exist followed by a UTC offset or the UTC zone designator (
Z). For more than information, see Time zones.
For instance, any of the following are valid timestamp values:
- 2018-08-19 12:11
- 2018-08-19 12:eleven:35
- 2018-08-xix 12:11:35.22
- 2018/08/19 12:eleven
- 2018-07-05 12:54:00 UTC
- 2018-08-xix 07:11:35.220 -05:00
- 2018-08-19T12:11:35.220Z
If y'all provide a schema, BigQuery also accepts Unix epoch fourth dimension for timestamp values. However, schema autodetection doesn't notice this case, and treats the value every bit a numeric or string type instead.
Examples of Unix epoch timestamp values:
- 1534680695
- 1.534680695e11
Array (repeated field). The value must exist a JSON assortment or null. JSON null is converted to SQL NULL. The assortment itself cannot comprise null values.
JSON options
To change how BigQuery parses JSON data, specify additional options in the Cloud Console, the bq control-line tool, the API, or the client libraries.
| JSON choice | Console selection | bq tool flag | BigQuery API belongings | Description |
|---|---|---|---|---|
| Number of bad records allowed | Number of errors immune | --max_bad_records | maxBadRecords (Java, Python) | (Optional) The maximum number of bad records that BigQuery can ignore when running the job. If the number of bad records exceeds this value, an invalid fault is returned in the chore result. The default value is `0`, which requires that all records are valid. |
| Unknown values | Ignore unknown values | --ignore_unknown_values | ignoreUnknownValues (Java, Python) | (Optional) Indicates whether BigQuery should allow extra values that are not represented in the tabular array schema. If truthful, the extra values are ignored. If false, records with actress columns are treated as bad records, and if there are also many bad records, an invalid error is returned in the job result. The default value is false. The `sourceFormat` belongings determines what BigQuery treats as an extra value: CSV: trailing columns, JSON: named values that don't lucifer any cavalcade names. |
Except every bit otherwise noted, the content of this page is licensed under the Creative Commons Attribution iv.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2022-04-13 UTC.
Source: https://cloud.google.com/bigquery/docs/loading-data-cloud-storage-json
0 Response to "How to Upload the json to a Cloudkey?"
Post a Comment